1. [파이썬] 셀레니움 selenium 웹 크롤링 시작 (이전 포스팅)
2. [파이썬] selenium 크롤링, 데이터 수집 ID, TAG, href 찾기 (현재 글)
3. [깃허브] github에 vs code project 올리기, 업로드, Push
4. 티스토리 자동 글쓰기 API Authentication Code & Access Token 발급
5. [파이썬] 티스토리 API 이용 자동 글쓰기. 파이썬 request post
6. [파이썬] 뉴스 크롤링 티스토리에 자동 업로드하기 (마무리)
7. [파이썬] 윈도우 작업 스케줄러에서 파이썬 자동 실행시키기
저번 포스팅에서 selenium 개발환경 설치하고 네이버 뉴스 링크로 들어오는 것까지 했다.
이번에는 들어온 링크에서 내가 원하는 데이터만 수집해오는 것을 해보려 한다.
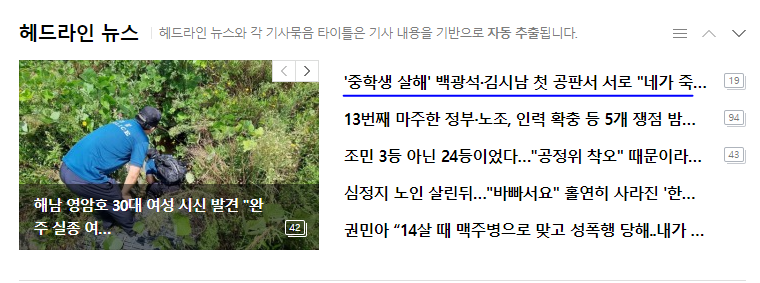
우선 별 의도는 없었으나 아무래도 헤드라인 뉴스이다 보니까 자극적인 내용들이 좀 있다...
아무튼 각설하고 내가 원한는 데이터는 저기의 뉴스 제목과 링크이다.
두 가지 데이터를 빼오기 위해 F12를 눌러 개발자 모드로 들어간다.
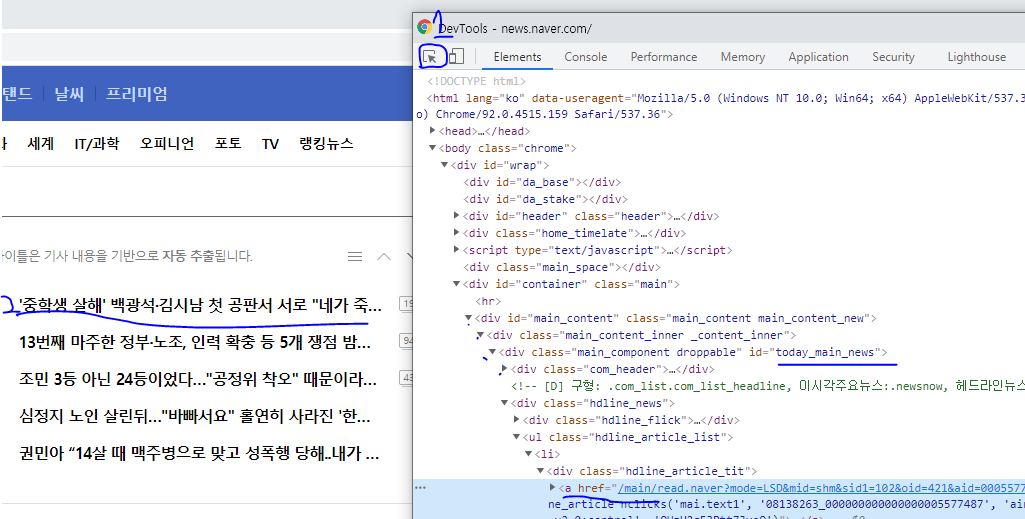
개발새발은 이해좀 해주길.... 우선 1번버튼 클릭하고 원하는 데이터를 얻을 2번 영역을 클릭한다.
그러면 우선 <a href 에 링크는 보인다. 저것을 빼와야 한다.
그리고 제목도 안보이는데 a 태그를 열어보면 내용이 나온다.
우선은 그러면 전체적인 구조를 다시 봐본다.
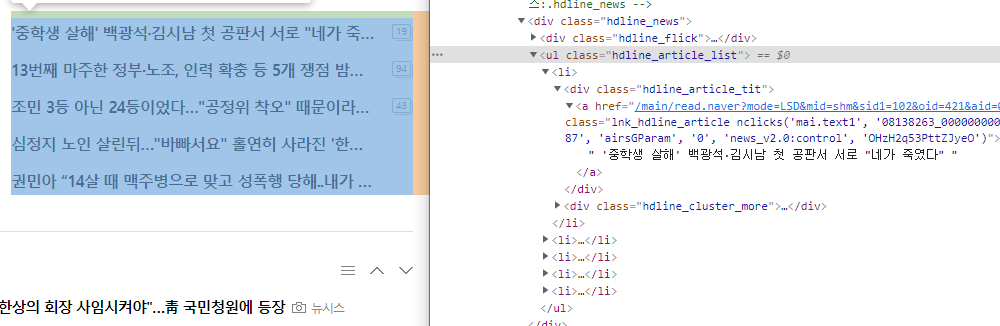
수집할 왼쪽에 data가 다섯개 있고 그 영역을 개발자모드로 찾으면 저렇게 <li>태그 여러개가 <ul>로 감싸져 있다.
이 위 사진을 보면 이 <ul>은 또 today_main_news 라는 id 값을 가진 <div> 안에 감싸져 있다.
이러면 찾기가 수월해진다.
<li>는 이 페이지에서 여러개 존재하기 때문에 그것만으로 찾아내기는 귀찮은데
명확한 id값을 가진 <div> 내에서 <li> 모음을 찾고 그 안에서 <a> 태그를 찾아 href를 얻고 text를 얻으면 링크와 제목을 얻게 된다.
찾는 순서 id -> li -> a -> href, text
이걸 코드로 구현해보자.

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
naverNewsUrl = 'https://news.naver.com/'
driver.get(naverNewsUrl)
# li를 감싼 div 검색
tmNews = driver.find_element_by_id('today_main_news')
# div 내에서 li 리스트 검색
tmNewsLis = tmNews.find_elements_by_tag_name('li')
# li는 여러개이므로 for문으로 루프
for li in tmNewsLis :
aTag = li.find_element_by_tag_name('a')
href = aTag.get_attribute('href')
print('기사 제목 :', aTag.text)
print('링크 : ', href)
|
cs |
5행 : 먼저 div의 id로 검색을 한다. driver.find_element_by_id('id')로 검색하여 tmNews에 담는다.
7행 : 주석처럼 검색한 div 내에서 tmNews.find_elements_by_tag_name('li')로 div 내 li 전부를 변수에 담는다.
하나를 검색할때는 element로 검색하고 맨 위에 값이 나온다.
여러개를 검색할 때는 elements 로 s를 붙여서 검색한다.
10행 : for문으로 검색된 <li> 태그 개수만큼 반복한다.
11행 : li 내에 있는 <a> 태그를 찾는다. 여기서는 a 태그 하나밖에 없고 하나만 필요하니 element로 검색한 것이다.
12행 : href는 태그가 아니라 <a> 태그 안에 있는 요소 이므로 get_attribute('href')로 검색하면 된다.
꼭 href가 아니라 src나 type 으로도 찾을 수 있다.
14행의 aTag.text로 <a> 태그 내에 택스트를 검색한다. 이 경우는 li안에 텍스트의 의미도 같으므로 li.text로 해도 결과값은 같다.
이렇게해서 돌리면

이렇게 제목과 링크를 수집했다. 이것을 이제 사용하고 싶은대로 가공하면 된다.
일단 졸리므로 여기까지
'Project > Auto Upload' 카테고리의 다른 글
| [파이썬] 뉴스 크롤링 티스토리에 자동 업로드하기 (마무리) (7) | 2021.09.24 |
|---|---|
| [파이썬] 티스토리 API 이용 자동 글쓰기. 파이썬 request post (2) | 2021.09.11 |
| 티스토리 자동 글쓰기 API Authentication Code & Access Token 발급 (2) | 2021.09.11 |
| [깃허브] github에 vs code project 올리기, 업로드, Push (0) | 2021.09.09 |
| [파이썬] 셀레니움 selenium 웹 크롤링 시작 (0) | 2021.08.31 |




댓글